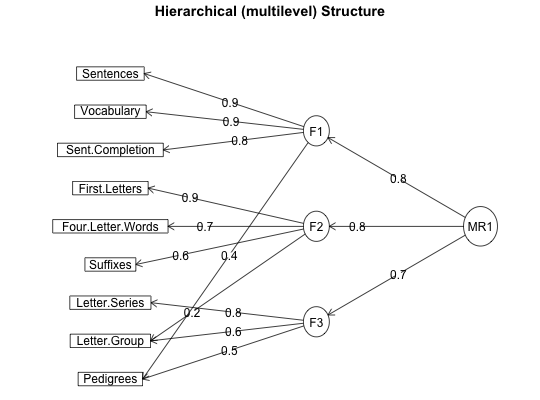
Multi level (hierarchical) factor analysis
Some factor analytic solutions produce correlated factors which may in turn be factored. If the solution has one higher order, the omega function is most appropriate. But, in the case of multi higher order factors, then the faMulti function will do a lower level factoring and then factor the resulting correlation matrix. Multi level factor diagrams are also shown.
fa.multi(r, nfactors = 3, nfact2 = 1, n.obs = NA, n.iter = 1, rotate = "oblimin", scores = "regression", residuals = FALSE, SMC = TRUE, covar = FALSE, missing = FALSE,impute = "median", min.err = 0.001, max.iter = 50, symmetric = TRUE, warnings =TRUE, fm = "minres", alpha = 0.1, p = 0.05, oblique.scores = FALSE, np.obs = NULL, use ="pairwise", cor = "cor", ...) fa.multi.diagram(multi.results,sort=TRUE,labels=NULL,flabels=NULL,cut=.2,gcut=.2, simple=TRUE,errors=FALSE, digits=1,e.size=.1,rsize=.15,side=3,main=NULL,cex=NULL,color.lines=TRUE ,marg=c(.5,.5,1.5,.5),adj=2, ...)
Arguments
| r | A correlation matrix or raw data matrix |
|---|---|
| nfactors | The desired number of factors for the lower level |
| nfact2 | The desired number of factors for the higher level |
| n.obs | Number of observations used to find the correlation matrix if using a correlation matrix. Used for finding the goodness of fit statistics. Must be specified if using a correlaton matrix and finding confidence intervals. |
| np.obs | The pairwise number of observations. Used if using a correlation matrix and asking for a minchi solution. |
| rotate | "none", "varimax", "quartimax", "bentlerT", "equamax", "varimin", "geominT" and "bifactor" are orthogonal rotations. "promax", "oblimin", "simplimax", "bentlerQ, "geominQ" and "biquartimin" and "cluster" are possible oblique transformations of the solution. The default is to do a oblimin transformation, although versions prior to 2009 defaulted to varimax. |
| n.iter | Number of bootstrap interations to do in fa or fa.poly |
| residuals | Should the residual matrix be shown |
| scores | the default="regression" finds factor scores using regression. Alternatives for estimating factor scores include simple regression ("Thurstone"), correlaton preserving ("tenBerge") as well as "Anderson" and "Bartlett" using the appropriate algorithms (see factor.scores). Although scores="tenBerge" is probably preferred for most solutions, it will lead to problems with some improper correlation matrices. |
| SMC | Use squared multiple correlations (SMC=TRUE) or use 1 as initial communality estimate. Try using 1 if imaginary eigen values are reported. If SMC is a vector of length the number of variables, then these values are used as starting values in the case of fm='pa'. |
| covar | if covar is TRUE, factor the covariance matrix, otherwise factor the correlation matrix |
| missing | if scores are TRUE, and missing=TRUE, then impute missing values using either the median or the mean |
| impute | "median" or "mean" values are used to replace missing values |
| min.err | Iterate until the change in communalities is less than min.err |
| max.iter | Maximum number of iterations for convergence |
| symmetric | symmetric=TRUE forces symmetry by just looking at the lower off diagonal values |
| warnings | warnings=TRUE => warn if number of factors is too many |
| fm | factoring method fm="minres" will do a minimum residual (OLS), fm="wls" will do a weighted least squares (WLS) solution, fm="gls" does a generalized weighted least squares (GLS), fm="pa" will do the principal factor solution, fm="ml" will do a maximum likelihood factor analysis. fm="minchi" will minimize the sample size weighted chi square when treating pairwise correlations with different number of subjects per pair. |
| alpha | alpha level for the confidence intervals for RMSEA |
| p | if doing iterations to find confidence intervals, what probability values should be found for the confidence intervals |
| oblique.scores | When factor scores are found, should they be based on the structure matrix (default) or the pattern matrix (oblique.scores=TRUE). |
| use | How to treat missing data, use="pairwise" is the default". See cor for other options. |
| cor | How to find the correlations: "cor" is Pearson", "cov" is covariance, "tet" is tetrachoric, "poly" is polychoric, "mixed" uses mixed cor for a mixture of tetrachorics, polychorics, Pearsons, biserials, and polyserials, Yuleb is Yulebonett, Yuleq and YuleY are the obvious Yule coefficients as appropriate |
| multi.results | The results from fa.multi |
| labels | variable labels |
| flabels | Labels for the factors (not counting g) |
| size | size of graphics window |
| digits | Precision of labels |
| cex | control font size |
| color.lines | Use black for positive, red for negative |
| marg | The margins for the figure are set to be wider than normal by default |
| adj | Adjust the location of the factor loadings to vary as factor mod 4 + 1 |
| main | main figure caption |
| … | additional parameters, specifically, keys may be passed if using the target rotation, or delta if using geominQ, or whether to normalize if using Varimax. In addition, for fa.multi.diagram, other options to pass into the graphics packages |
| e.size | the size to draw the ellipses for the factors. This is scaled by the number of variables. |
| cut | Minimum path coefficient to draw |
| gcut | Minimum general factor path to draw |
| simple | draw just one path per item |
| sort | sort the solution before making the diagram |
| side | on which side should errors be drawn? |
| errors | show the error estimates |
| rsize | size of the rectangles |
Details
See fa and omega for a discussion of factor analysis and of the case of one higher order factor.
Value
The standard output from a factor analysis from fa for the raw variables
The standard output from a factor analysis from fa for the correlation matrix of the level 1 solution.
References
Revelle, William. (in prep) An introduction to psychometric theory with applications in R. Springer. Working draft available at http://personality-project.org/r/book/
Note
This is clearly an early implementation (Feb 14 2016) which might be improved.
See also
Examples
f31 <- fa.multi(Thurstone,3,1) #compare with \code{\link{omega}} f31#> $f1 #> Factor Analysis using method = minres #> Call: fa(r = r, nfactors = nfactors, n.obs = n.obs, rotate = rotate, #> scores = scores, residuals = residuals, SMC = SMC, covar = covar, #> missing = missing, impute = impute, min.err = min.err, max.iter = max.iter, #> symmetric = symmetric, warnings = warnings, fm = fm, alpha = alpha, #> oblique.scores = oblique.scores, np.obs = np.obs, use = use, #> cor = cor) #> Standardized loadings (pattern matrix) based upon correlation matrix #> MR1 MR2 MR3 h2 u2 com #> Sentences 0.90 -0.03 0.04 0.82 0.18 1.0 #> Vocabulary 0.89 0.06 -0.03 0.84 0.16 1.0 #> Sent.Completion 0.84 0.03 0.00 0.74 0.26 1.0 #> First.Letters 0.00 0.85 0.00 0.73 0.27 1.0 #> Four.Letter.Words -0.02 0.75 0.10 0.63 0.37 1.0 #> Suffixes 0.18 0.63 -0.08 0.50 0.50 1.2 #> Letter.Series 0.03 -0.01 0.84 0.73 0.27 1.0 #> Pedigrees 0.38 -0.05 0.46 0.51 0.49 2.0 #> Letter.Group -0.06 0.21 0.63 0.52 0.48 1.2 #> #> MR1 MR2 MR3 #> SS loadings 2.65 1.87 1.49 #> Proportion Var 0.29 0.21 0.17 #> Cumulative Var 0.29 0.50 0.67 #> Proportion Explained 0.44 0.31 0.25 #> Cumulative Proportion 0.44 0.75 1.00 #> #> With factor correlations of #> MR1 MR2 MR3 #> MR1 1.00 0.59 0.53 #> MR2 0.59 1.00 0.52 #> MR3 0.53 0.52 1.00 #> #> Mean item complexity = 1.2 #> Test of the hypothesis that 3 factors are sufficient. #> #> The degrees of freedom for the null model are 36 and the objective function was 5.2 #> The degrees of freedom for the model are 12 and the objective function was 0.01 #> #> The root mean square of the residuals (RMSR) is 0.01 #> The df corrected root mean square of the residuals is 0.01 #> #> Fit based upon off diagonal values = 1 #> Measures of factor score adequacy #> MR1 MR2 MR3 #> Correlation of scores with factors 0.96 0.92 0.90 #> Multiple R square of scores with factors 0.93 0.85 0.82 #> Minimum correlation of possible factor scores 0.86 0.71 0.63 #> #> $f2 #> Factor Analysis using method = minres #> Call: fa(r = f1$Phi, nfactors = nfact2, rotate = rotate) #> Standardized loadings (pattern matrix) based upon correlation matrix #> MR1 h2 u2 com #> MR1 0.78 0.61 0.39 1 #> MR2 0.76 0.57 0.43 1 #> MR3 0.68 0.46 0.54 1 #> #> MR1 #> SS loadings 1.65 #> Proportion Var 0.55 #> #> Mean item complexity = 1 #> Test of the hypothesis that 1 factor is sufficient. #> #> The degrees of freedom for the null model are 3 and the objective function was 0.86 #> The degrees of freedom for the model are 0 and the objective function was 0 #> #> The root mean square of the residuals (RMSR) is 0 #> The df corrected root mean square of the residuals is NA #> #> Fit based upon off diagonal values = 1 #> Measures of factor score adequacy #> MR1 #> Correlation of scores with factors 0.89 #> Multiple R square of scores with factors 0.79 #> Minimum correlation of possible factor scores 0.58 #>fa.multi.diagram(f31)